
Beowulf Cluster ATOM
작성자 정보
- 웹관리자 작성
- 작성일
컨텐츠 정보
- 11,685 조회
- 0 추천
- 목록
본문
|
신순철 / scshin@mail.suwon.ac.kr | ||||||||||||||||||||||||||||||||||||||||||||||||
|
목차 0. 들어가기에 앞서
0. 들어가기에 앞서 베어울프 클러스터란 리눅스와 PC들을 이용해서 제작한 병렬시스템을 말한다. 여러 대의 컴퓨터의 컴퓨팅 파워를 모아서 하나의 거대한 슈퍼컴퓨터를 만드는 개념이다. 베어울프 클러스터는 구조(분산 메모리, 다중 프로세서)와 프로그램방식(메시지패싱방식)이 같기 때문에 종종 슈퍼컴퓨터(MPP 방식의)와 비교되곤 한다. 베어울프 클러스터는 슈퍼컴퓨터가 전용 하드웨어를 사용하는데 비해 범용 하드웨어를 사용함으로써 저렴한 가격에 구성할 수 있으며 범용 하드웨어의 급속한 발달로 인해 좋은 성능을 낸다는 장점을 가지고 있다. 베어울프 클러스터에 대해 낯설은 사람들이 가지고 있는 위험한 생각은 모든 문제에 있어서 좋은 해결책일 것이라 생각하는 것이다. 사실은 그렇지 않다. 대부분의 응용프로그램에 있어서 베어울프 클러스터는 좋은 해결책이 아니다. 베어울프 클러스터가 주로 사용되는 분야는 시뮬레이션 분야이다. 해양, 기후, 유체 등을 시뮬레이션하는 분야에 주로 사용되고 있으며 이는 자연과학이나 공학분야에서 많이 사용된다. 이 때문에 전산학도 중에는 베어울프 클러스터에 대해 오히려 모르는 경우가 많다. 따라서 베어울프 클러스터를 사용하기 위해서는 병렬화된 코드가 있어야 된다. 자신이 직접 만들거나 얻어오는 방법이 있을 것이다. 본 문서에서는 직접 제작하여 사용하고 있는 베어울프 클러스터 아톰(ATOM)에 대한 소개와 제작 방법, 슈퍼컴퓨터와의 성능 비교분석을 다루고자 한다. 베어울프 클러스터의 제작기술은 이미 인터넷의 여러 곳에 공개되 있으며 실제 연구에 활용하고 있는 곳도 많이 있다. 따라서 제작방법에 대한 자세한 설명은 하지 않을 것이며 큰 줄거리만을 다룰 것이다. 그리고 이 문서에서 언급하는 것에 대한 보다 자세한 설명은 더 나은 참고문서를 소개하는 것으로 대체할 것이다. 베어울프 제작에 관심이 있고 단지 하나의 기술 문서가 필요하다면 아래의 문서가 매우 유용할 것이다. Beowulf Installation and Administration HOWTO COCOA Beowulf Cluster FAQ
1. 아톰의 사양
NETWORK DEVICE 각 노드는 1개의 100M 이더넷카드를 장착했으며 100M Switching hub 에 물려있다. 또한 마스터노드는 2개의 이더넷카드를 달아서 하나는 외부 네트워크에 연결 되있다. 제작비(2000년 1월기준) 노드당 약 80만원정도(슬레이브 기준)가 소요됐으며,네트워크 장비를 구입하는데 200만원정도가 소요됐다.
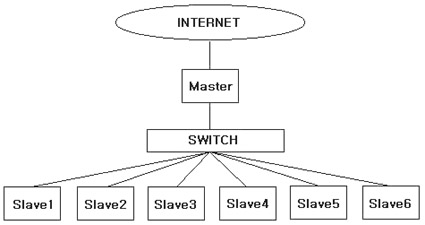
2. Topology(위상) 아톰은 그림과 같이 한 개의 마스터노드와 6개의 슬레이브노드해서 총 7개의 노드로 구성 되있으며 각 노드가 dual cpu 이므로 총 14개의 프로세서를 가지고 있다. 서브 네트워크를 구축하는 것은 외부의 패킷이 각 노드간의 통신에 영향을 미치지 못하게 함으로써 노드간의 통신성능이 향상되는 장점이 있으며 원격사용자의 접근을 한 곳으로 제한함으로써 일괄적인 관리가 가능하다.
위의 그림과 같은 네트워크 연결은 노드간에 메시지 패싱에 걸리는 시간은 모두 동일하며 따라서 병렬 프로그래밍에 있어서 네트워크 위상에 대해서는 별도의 신경을 쓸 필요가 없다.
3. Setup 1) 각 노드를 네트워크에 연결한다. 병렬시스템을 구성하기 위해서는 각 노드간에 통신을 할 수 있는 환경이 조성되어야 한다. 따라서 각 노드는 네트워크에 연결돼있든가 사설 네트워크를 구축해야 한다.
2) 각 노드에 병렬 라이브러리를 설치한다. 노드간의 실제통신은 MPI(Message Passing Interface) 또는 PVM(Parall Virtual Machin)라는 라이브러를 통해서 이루어진다. MPI는 국제화 표준이 정의되어 있고, PVM보다 빠른 통신성능을 제공하는 잇점이 있으며 PVM은 이 기종간의 호환이 좋은 것으로 알려져 있다. 현재 추세는 MPI 쪽으로 흐르는 것 같다. MPICH 홈페이지 LamMPI 홈페이지 PVM 홈페이지
3) 이것으로 기본적인 병렬시스템의 구축이 끝났다. 하지만 좀더 나은 성능과 사용의 편이성을 위해서는 몇 가지 더 해주어야 할 것이 있다.
4) 네트워크를 외부와 격리시킨다. 이것은 외부의 패킷이 클러스터의 컴퓨터에 부하를 주지 않도록 하기 위해서 대부분의 클러스터에서 채택되고 있다.
5) 채널 본딩을 한다. 밑에서 살펴보겠지만 클러스터의 성능은 노드간의 통신성능에 많은 영향을 받으며, 통신성능이 매우 뛰어나다고 할지라도 많은 경우에 병목구간으로 작용한다. 하지만 무작정 고속의 통신성능을 제공하기 보다는 가격 대 성능비에 맞추어서, 그리고 사용자의 필요에 맞추어 적당한 통신장비를 장착해야 한다. 일반적으로 100Mbps급의 스위칭허브를 많이 사용하고 있으며 노드당 2개의 랜카드를 채널본딩(2개의 랜카드에 하나의 IP부여)하여 2배의 처리량을 확보해주고 있다. 더 좋은 통신 성능을 내기 위해서는 미리넷, 기가비트이더넷, ATM 등을 고려해볼 수 있다. 채널 본딩 관련 사이트 미리넷 사이트 ATM 사이트
6) TCP 패치를 한다. 클러스터에 사용되는 OS는 대부분 리눅스를 사용한다. 그러나 리눅스는 작은 크기의 데이터를 전달할 때 다음에 또다른 데이터가 기대되면 그것을 기다렸다가 같이 패킷에 넣어서 보내게 된다. 작은 크기의 메시지를 발생하는 경우는 대부분 네트워크 용량이 남게 되는데 굳이 여러 개의 데이터를 팩하기 위해서 대기하는 것은 결국 통신속도의 저하를 가져오게 된다. 이것을 보완한 클러스터 용 TCP 패치가 있으며 이것은 작은 메시지패싱에 있어서 약 50%정도의 성능 향상을 가져온다. TCP패치 사이트
7) NFS를 이용한 공유 클러스터의 단점 중 하나는 노드 수가 늘어날수록 관리하기가 어렵다는 것이다. 만약 64개의 노드로 구성된 클러스터를 관리한다고 가정해보자. 새로운 버전의 MPI가 나왔다면 관리자는 이를 사용하기 위해 64번의 인스톨을 해주어야 한다. 이것에 필요한 노력과 HDD 용량의 낭비가 심하다. 일반적으로 사용하는 프로그램이 파일 입출력이 많지 않거나 프로그램의 시작이나 끝 등 특정부분에서만 필요하다면 하나의 마스터노드에만 프로그램을 설치하고 나머지 대부분의 머신을 HDD없이 꾸미고 마스터노드를 NFS마운트하여 구성하는 것을 고려해 볼만하다. 사실 매우 많은 베어울프 클러스터는 이러한 형태로 구성된다. 아톰의 경우 역시 7노드중에 마스터노드에만 물리적인 HDD가 장착 되있으면 나머지 노드들은 NFS를 통하여 마스터노드의 HDD의 데이터를 사용하고 있다. 이것은 한번의 프로그램 설치만으로 모든 노드가 이 프로그램을 사용할 수 있으며, 사용자 입장에서는 7개의 홈디렉토리가 실제는 하나의 물리적인 공간이므로 사용하기 편리하다. 이것은 네트워크 부하를 증가시키는 단점이 있지만 사용과 관리의 편이상 많이 사용되고 있다. 그러나 대규모 클러스터에서는 한 개의 HDD를 수십 수백개의 노드가 공유하는 것은 심각한 병목현상을 초래하므로 다수의 HDD를 가진 노드와 다수의 디스크리스(diskless) 노드를 가진 중간의 경우도 생각해 볼 수 있다. Diskless 리눅스 박스 설치 문서
8) 사용자의 편이를 제공하는 프로그램들 병렬프로그램을 모니터링 할 수 있는 그래픽 툴 들이 나와있다. 등이 많이 사용되는 것들이다.
4. Benchmarking 아톰을 나사에서 제공하는 벤치마크 프로그램인 NPB를 사용하여 성능을 테스트해 보았다. NPB2.0(NasaParallelBenchmarking Version 2.0) NPB 홈페이지
CPU 갯수가 다른 것은 대부분의 문제는 특정한 개수의 프로세서를 요구한다. 따라서 전체 프로세서를 사용하여 테스트하지 못하고 허락되는 한도에서 테스트했기 때문이다. 그리고 CLASS는 문제의 크기를 나타내는데 W,A,B,C.. 순으로 갈수록 문제의 크기가 커진다. 일반적으로 대규모, 고속의 머신들을 테스트하는데 사용하므로 문제 사이즈가 매우 크다. 그러나 ATOM은 메모리가 128M이므로 씨리얼 프로그램으로 잘해야 A나 W를 테스트할 수 있었다. 그러나 ATOM은 개개의 머신으로써는 128M 내지는 256M의 메모리를 갖지만 클러스터로써의 ATOM은 약 1G의 메모리를 가지고 있으므로 병렬로 돌릴 경우에는 물론 그이상의 크기의 문제도 테스트할 수 있었다. EP는 random number generation을 하는 테스트로써 각 노드간에 통신이 없으므로 14 개의 프로세서를 사용할 경우 14배의 성능이 나올 것이 기대되지만 ATOM의 각 노드는 SMP(Symetric Multi Process)이므로 메모리에서 병목현상으로 인해 약간의 성능저하가 발생했다. 만약 7개의 노드에서 각 하나씩의 프로세서를 사용하여 총 7개의 프로세서로 실행하면 정확하게 7배의 성능이 나온다. BT는 메시지 패싱회수는 많지 않지만 메시지크기가 매우 큰 것이 특징이다. 따라서 이 테스트는 노드간의 통신 성능이 결과에 큰 영향을 미친다. 고성능 네트워크 장비를 갖춘다고 하더라도 통신문제는 언제나 병목구간으로 작용하곤 한다. 또한 SMP에서는 하나의 노드 안에 있는 여러 개의 프로세서가 하나의 네트워크라인을 공유하게 되므로 이러한 문제가 더욱 크다. 위의 벤치마크에서도 7노드에서 9개의 프로세서를 사용했으므로 2개의 노드는 프로세서당 50Mbps급의 통신성능을 가진 셈이 됐다. 그러나 이것은 결국 전체 노드가 저 성능의 노드에 동기화되므로 모든 노드가 50Mbps급의 통신성능을 가지고 수행된 것과 마찬가지이다. 표에서 보면 4개의 프로세서를 사용하여 테스트한 결과가 있는데 이것은 각 프로세서가 100Mbps급의 통신성능을 가지고 수행된 것을 의미하며 따라서 MOP/cpu(프로세서당 연산량)이 증가하는 것을 볼 수 있다. LU는 작은 크기의 메시지를 대량으로 발생시키는 문제이다. 이것은 네트워크 성능보다는 MPI 라이브러리가 작은 메시지를 얼마나 효율적으로 처리하는가에 달려있다. 따라서 노드당 100Mbps급의 통신성능을 확보해준다고 하더라도 MOP/cpu는 BT테스트에 비해 성능향상이 적다. 일반적으로 작은 크기의 메시지 처리에 있어서는 LamMPI가 MPICH보다 강하다고 한다. 그 외에 해볼만한 벤치마킹은 아래와 같다. Linux/Unix nbench(리눅스 유닉스 성능 벤치마킹) NetPIPE(네트워크 벤치마킹)
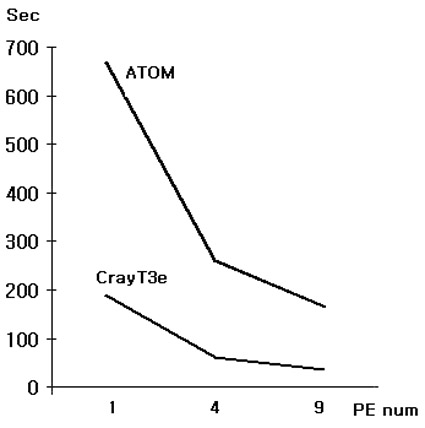
5. CrayT3e 와 비교 KORDIC에서 보유하고 있는 CrayT3e는 2000년 5월 현재 국내에서 가장 빠른 슈퍼컴퓨터이며 간단한 스펙은 아래와 같다. CPU : 136(DEC Alpha 450Mhz)개 System PE(8) + User PE(128) 2개의 프로그램을 사용하여 테스트를 했는데, 하나는 직접 작성한 작은 프로그램이며 작은 메시지를 발생시키는 프로그램이다. 4개의 프로세서를 사용하여 테스트한 결과는 CrayT3e에서는 69초만에 답을 얻었으며, ATOM Cluster에서는 131초만에 답을 얻었다. 슈퍼컴퓨터에 비해 약 50%의 성능을 내고 있다. 사실 이 테스트는 ATOM에게 매우 유리한 테스트이다. 일반적으로 Alpha칩은 동일 클럭의 Intel에 비해 2.5배정도의 빠른 성능을 갖고 있지만 integer나 32bit floating 에서는 64bit의 장점을 충분히 살리지 못한다. 또한 Crayt3e의 장점인 고속 네트워크도 작은 통신이 필요한 환경이므로 크게 유리하게 작용하지 못했다.
반면 대규모 메시지를 발생시키는 해양예보 프로그램인 POM의 경우는 다양한 개수의 프로세서에서 수행해서 비교해 보았다. 위의 표에서 보면 하나의 프로세서에서 테스트할 때는 약 3.5배 CrayT3e가 빨랐는데, 프로세서 4개에서는 약 4.3배, 프로세서 9개에서는 약 5.5배 빨라지는 것을 볼 수 있다. http://alpha-cluster.linuxone.co.kr/paper/NPB/npb.html
6. 클러스터의 발전방향 위에서 슈퍼컴퓨터와의 비교를 통해 클러스터가 어떤 경우에 효율적인지를 알 수 있었다. 이것은 클러스터가 어떤 작업에 효율적일지를 잘 알려주고 있다. 노드간에 통신이 적은 작업에 있어서는 탁월한 가격대 성능비를 보여주고 있다. 노드간의 통신이 많은 경우는 슈퍼컴퓨터에 비해 매우 낮은 성능을 보이고 있는데 이는 기가비트 이더넷이나 미리넷과 같은 고속의 네트워크 장비를 장착함으로서 좀더 나은 성능을 낼 수 있을 것이다. 클러스터의 시작은 일반적으로 사용되는 H/W를 사용함으로써 가격을 낮추고, 이들을 묶음으로써 성능을 높이고자 하는 시도에서 시작됐으며 이것이 같은 MPP머신이지만 전용 H/W를 사용하여 성능을 높이고 있는 슈퍼컴퓨터와의 근본적인 차이점이며 따라서 슈퍼컴퓨터의 성능에 미치지 못하는 것이 당연한지도 모르겠다. 하지만 요즘에는 미리넷과 같은 클러스터전용의 H/W가 등장했으며, 클러스터가 대중화되면서 가격이 많이 다운되고 있고 또한 클러스터의 뛰어난 확장성의 장점 때문에 슈퍼컴퓨터에 대한 도전은 계속될 것이다.
7. 기타 참고사이트 Beowulf Project 홈페이지 Beowulf에 관련된 다양한 프로그램 제공 Kaist의 클러스터 동호회의 링크페이지 리눅스원의 HPC팀 홈페이지 TOPCAT 클러스터 Linux Parallel Processing HOWTO | ||||||||||||||||||||||||||||||||||||||||||||||||
관련자료
-
이전
-
다음


